CQuery: CudangTangTang Trino와 엄지척
Hive+Tez 대 트리노
- Hive에 비해 매우 빠른 SQL 쿼리 성능
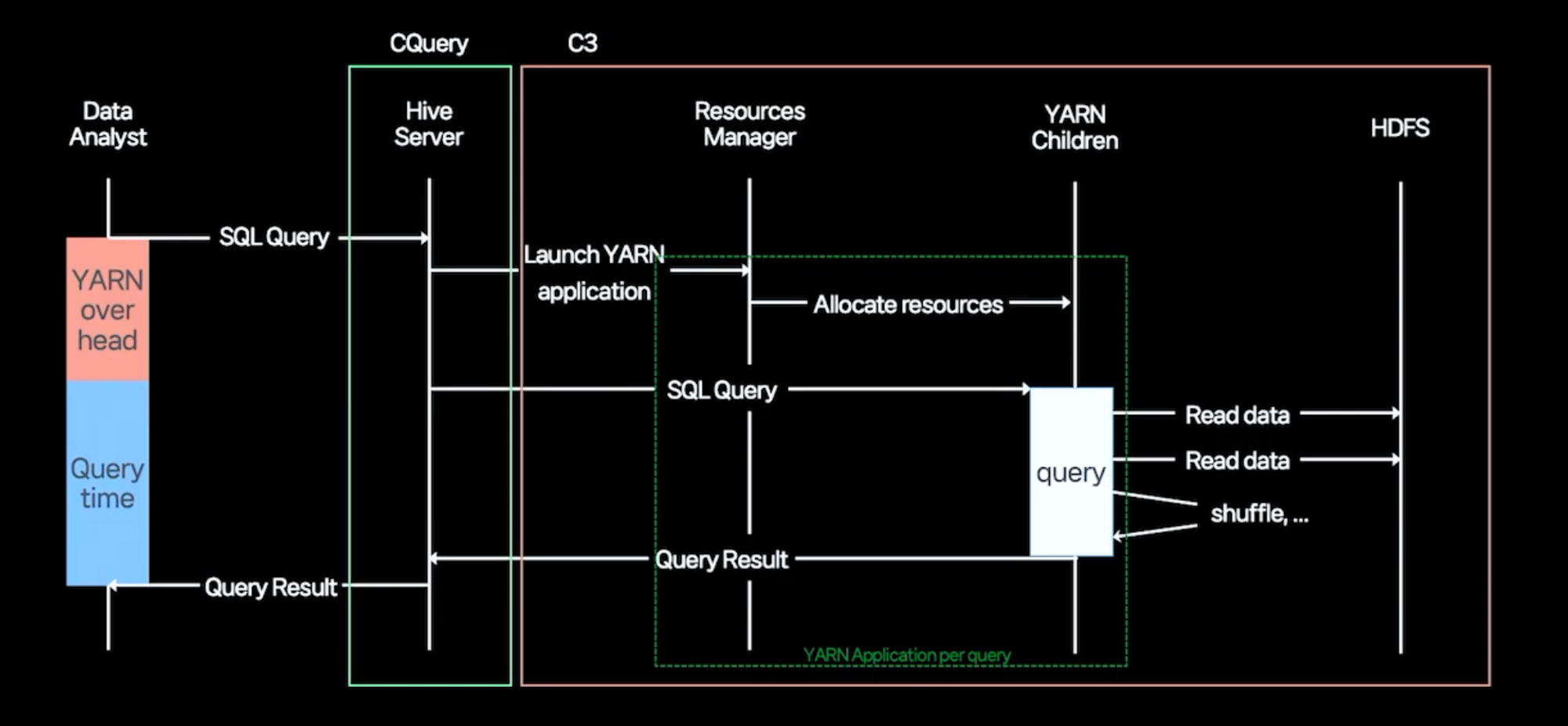
- Hive는 Yarn에서 리소스를 수신하고 HDFS 클러스터에서 데이터를 검색하며 쿼리를 처리하므로 Yarn 오버헤드와 쿼리 시간을 합한 시간이 총 처리 시간이 됩니다.
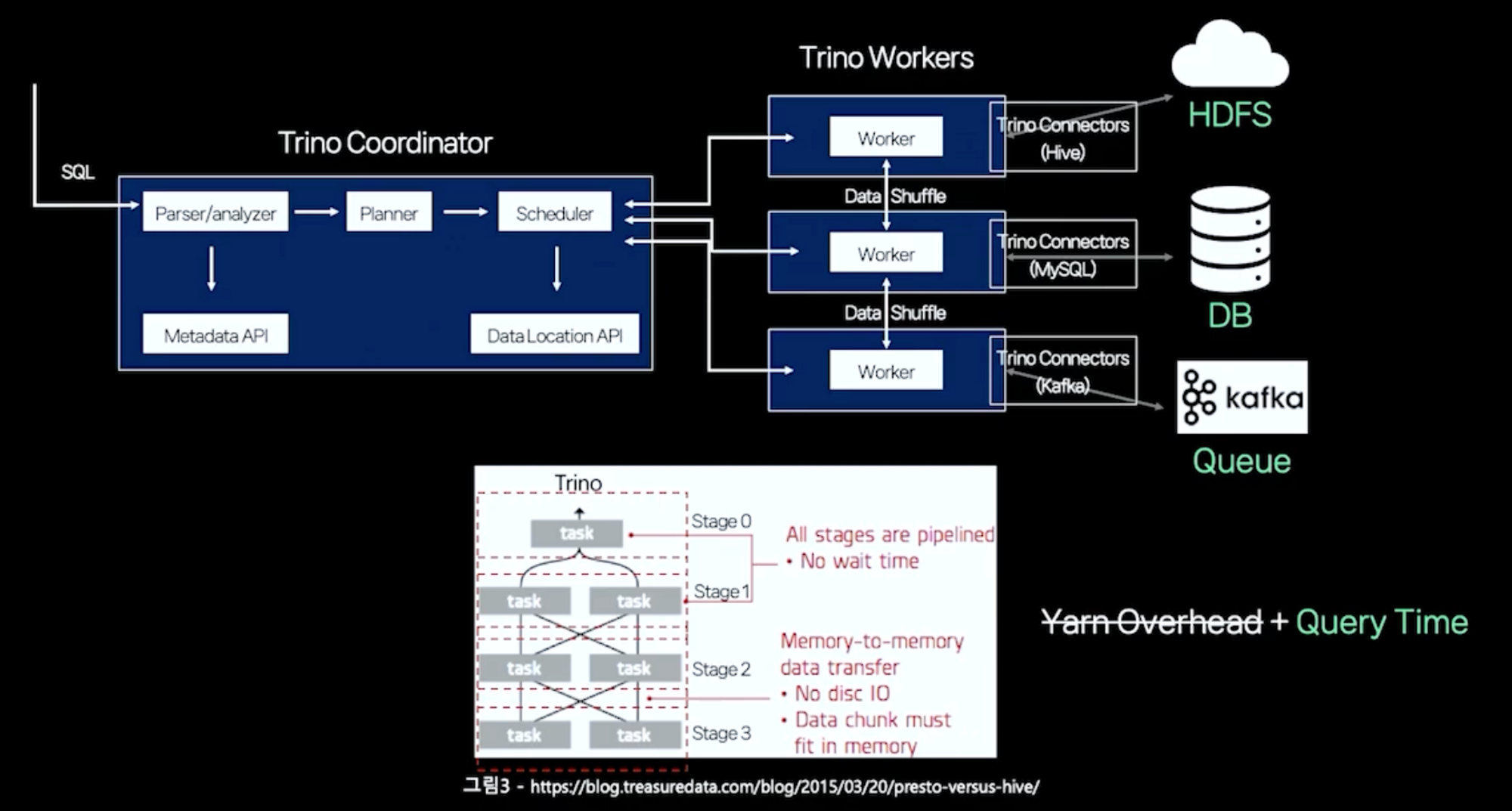
- JVM에서 실행되기 때문에 실 오버헤드가 없습니다.
- 코디네이터에서 필요한 메타데이터를 검색하고 최적화된 쿼리 계획을 생성합니다.
- 스케줄러에서 데이터 위치 정보는 작업 할당 시 작업자에게 전달됩니다.
- 작업자는 커넥터로 나누어 여러 DB에서 데이터를 읽고 쓸 수 있습니다.
- 데이터는 작업자의 메모리에 로드되고 여러 단계로 나누어진 관형 단위로 처리됩니다.
트리노 함수
- 20%는 커널, 디스크/네트워크 버퍼 등에 사용됩니다.
- 스레드 스택, GC, 오프힙 메모리 등으로 30% 사용
- 물리적 Starburst 쿼리의 실제 처리에 사용 가능한 메모리는 서버의 56%입니다.
- 예) 100GB 서버 → 80GB JVM(-20%) → 56GB 쿼리 메모리(-30%) → 총 손실 44GB(-44%)
- 작업자에서 처리되는 객체는 Pages > Blocks > Slices로 구분되어 처리됩니다.
- 슬라이스는 메모리에 액세스하고 특정 데이터에서 읽는 라이브러리입니다.
- 코디네이터의 WEB UI는 DB가 아닌 코디네이터의 메모리에 저장되어 날아갑니다.

- access-rules.json 파일은 WEB UI에 표시되는 쿼리에 대한 쿼리 액세스를 제한합니다.
- 재시도 정책: 실패한 쿼리 작업을 자동으로 재시도합니다.
- 내결함성 실행 옵션 설정 활성화
- 불필요한 특정 작업에 대한 재시도를 사용자가 임의로 비활성화할 수 있습니다.
- Level 0: 코디네이터에서만 실행되는 작업, Level 1 작업 결과의 최종 집계
- N단계(1) : 작업자별 업무를 수행하는 분산형 단계
작전
- GC는 Web UI 히스토리 개수만큼 자주 실행되지 않기 때문에 개수를 너무 늘리면 OOM, 서버 무응답 등의 오류가 발생한다.
- JMX에서 제공하는 인디케이터를 Prometheus와 연동하여 사용
- Elasticsearch와 이벤트 리스너를 통해 쿼리별 실행 정보 통합
- 실행된 쿼리 정보
- 사용된 리소스 정보
- 쿼리 실패 예외 정보
- 이벤트 리스너
- Query Creation: 사용자 쿼리가 입력되어 실행되기 전에 발생하는 이벤트
- 쿼리 완료: 사용자 쿼리가 완료된 후 발생하는 이벤트입니다.
- 분할 완료: 쿼리 실행 중 각 단계에 대한 분할이 완료될 때마다 발생하는 이벤트입니다.

- 이벤트 리스너 구현 및 사용
- 리소스 그룹: 대기열 정책을 적용하거나 그룹 내에서 실행 중인 쿼리에 대해 CPU 메모리 제한을 부여하는 기능
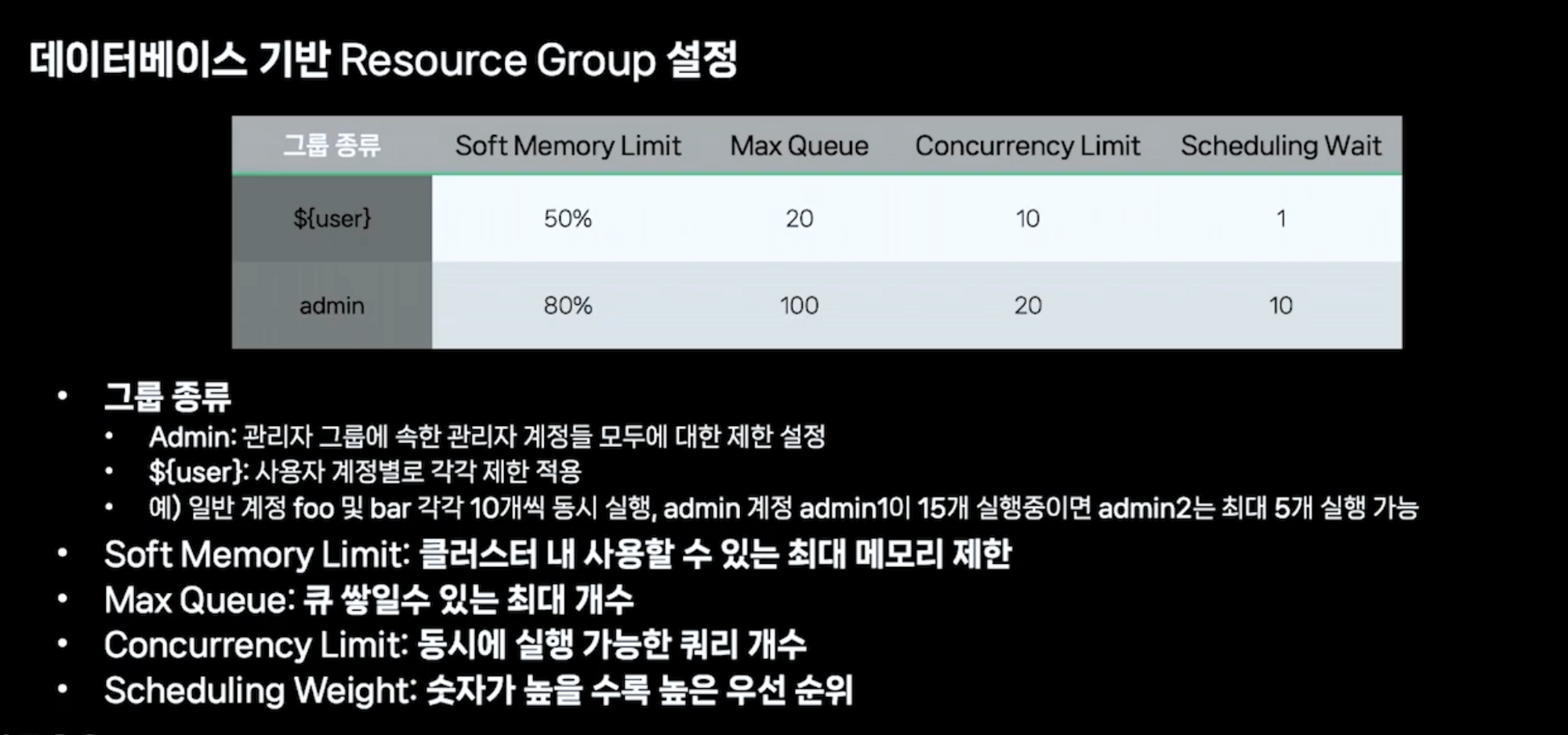
- 특정 사용자의 문제를 악용하는 다중 쿼리(for 문을 통해 마침표만 변경하여 대량의 쿼리 요청)
- 짧은 시간에 많은 요청으로 인한 시스템 불안정성
- 가드: 악의적인 쿼리로 인해 클러스터 리소스가 모두 소모되는 경우 발생
- 특정 작업자 기기의 장기간 CPU 부하 과부하로 인한 클러스터 데이터 처리 지연
- count(distinct) 함수는 고유한 값을 찾기 위한 로직이므로 대용량 문서에서도 approx_distinct() 함수를 사용하는 것이 좋습니다.


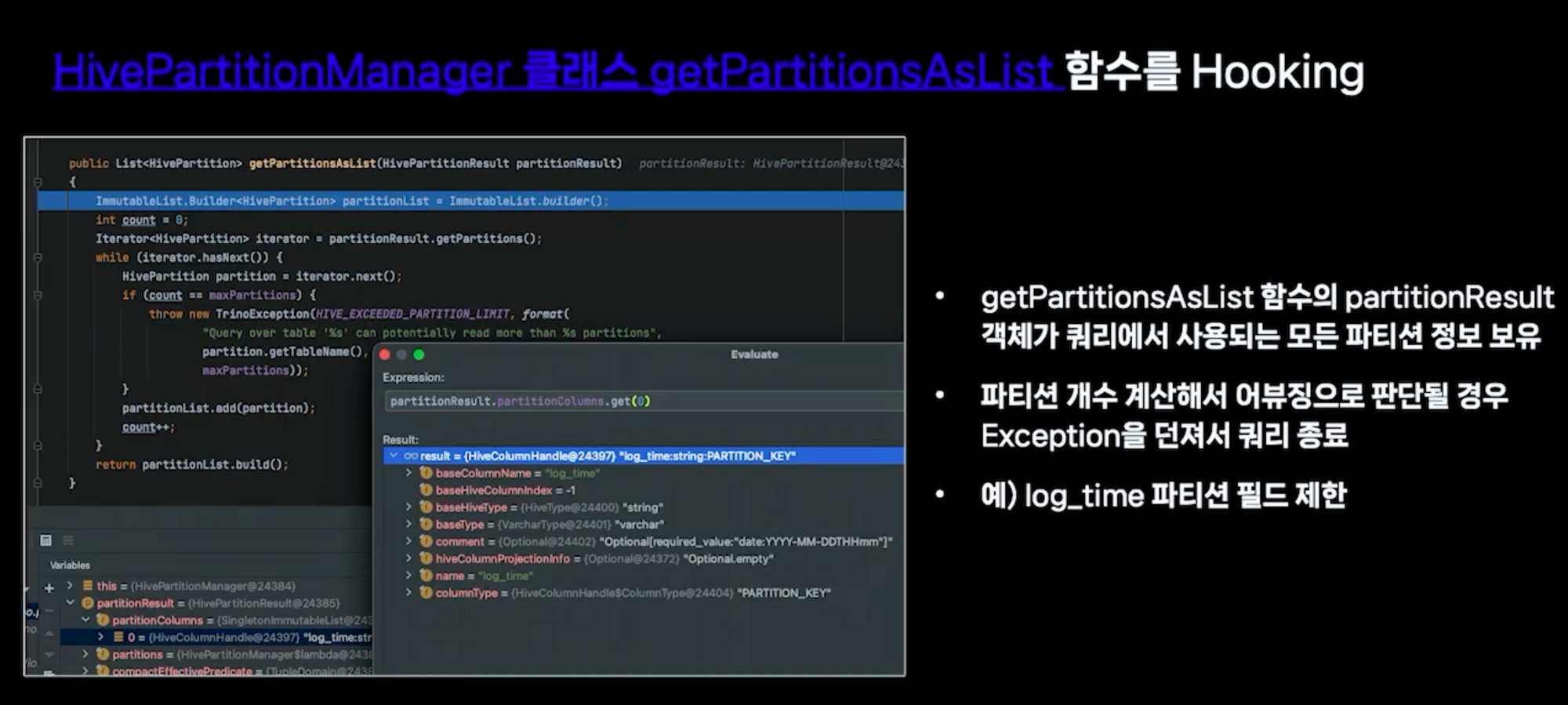
- 검색 기간이 제한 내이면 쿼리가 정상적으로 실행됩니다.
- UNION, JOIN 등 과도한 메모리 사용량으로 여전히 장애 발생 → SPil-to-Disk 기능 사용(운영체제 페이징과 유사한 기능) → 임시 메모리 사용량 한도 초과 가능
BE
- scale out에 한계가 있어 확장을 시도함 → dram보다 느리지만 저렴한 cxl 기반 메모리 사용

- 낮은 용량에서 CXL 메모리는 실제로 성능을 저하시킵니다.
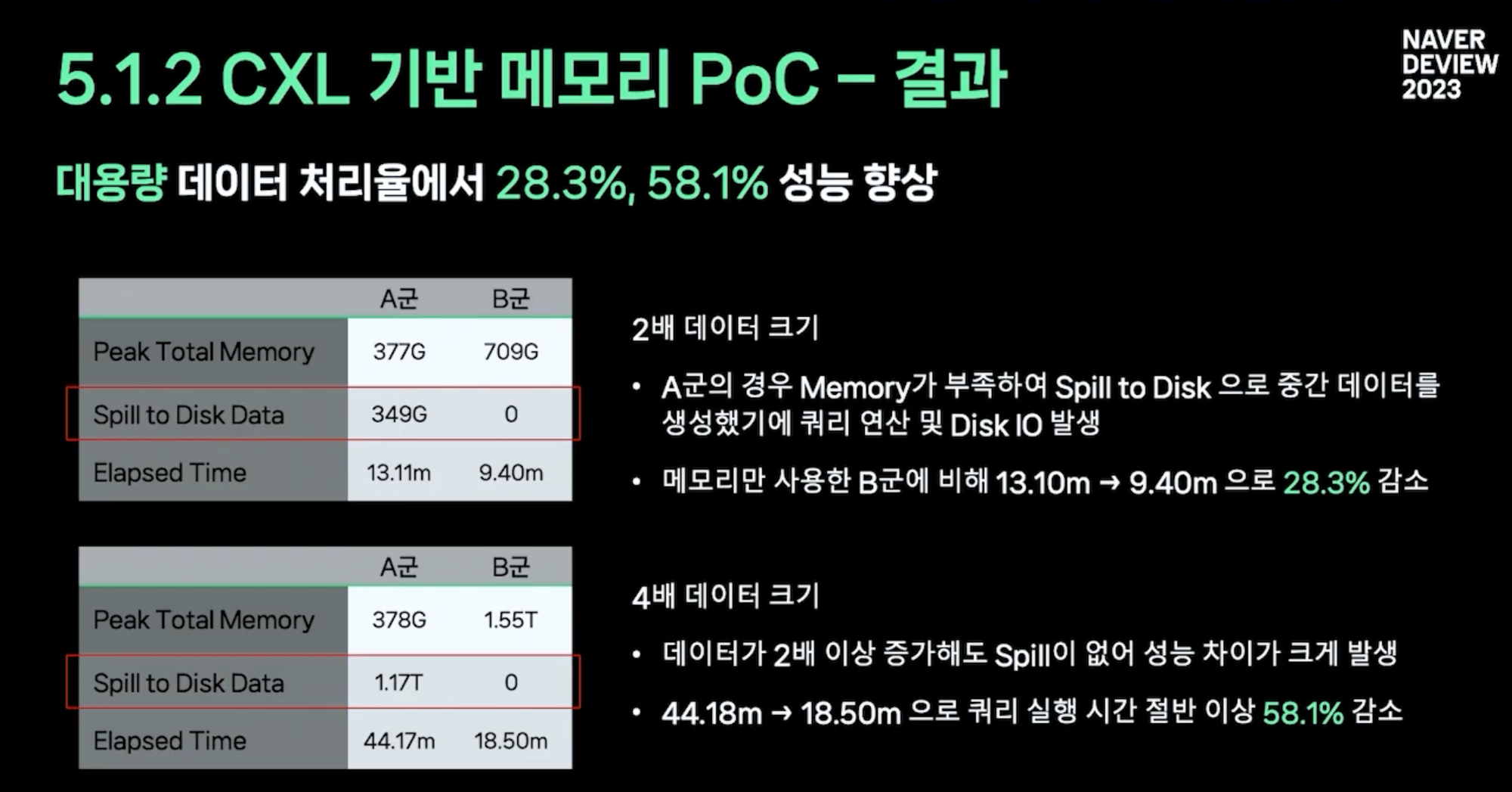
- 저가형 CXL 스토리지 확장으로 인한 데이터 유출 없음 디스크 I/O 사용빈도 감소로 빠른 쿼리 성능 기대 가능

- Lyft와 마찬가지로 쿼리 특성에 따라 자동으로 클러스터를 전환하는 프록시 게이트웨이 도입
- 성공을 보장해야 하는 쿼리는 별도의 클러스터에서 실행됩니다.
- Hive 테이블 형식에서 Iceberg 형식으로 전환
- Hive MetaStore의 RDBMS와 Hadoop NameNode 병목 현상은 PB 단위를 넘어 지속적으로 증가하는 데이터의 가장 큰 문제입니다.
Kafka 컨슈머를 네이버 스케일과 함께 사용하기
이것이 Kafka Consumer의 작동 방식입니다.
- 주제: 하나 이상의 파티션으로 분할, 하나 이상의 복제본으로 복제된 로그 데이터 구조
- 고객
- Producer: 쓸 토픽 파티션 끝에 레코드 추가
- 소비자: 읽고자 하는 토픽의 파티션에 저장된 레코드를 순차적으로 읽는다.
- 카프카란? 로그 데이터를 분산 저장 형태로 만들기
- 로그는 레코드가 추가된 순서대로 저장되는 데이터 구조 → 가장 큰 특징은 순서 보장
- Kafka에서 제공하는 로그는 분할 및 복제된 로그(파티션, 복제본)입니다.
- 고가용성, 단일 파티션 내에서만 주문 보장, 읽기-쓰기-읽기 복제 전용
- 소비자는 하나의 파티션만 읽습니다.
- 소비자가 함께 노력해야
- 소비자 그룹
- group.id 구성 값이 동일한 소비자는 소비자 그룹을 형성합니다.
- 동일한 컨슈머 그룹에 속한 컨슈머는 토픽에 속한 파티션을 공유하고 읽습니다.
- 소비자 재조정이 소비자 또는 파티션을 늘리거나 줄이면 자동으로 중지되고 조정 후 시작됩니다.
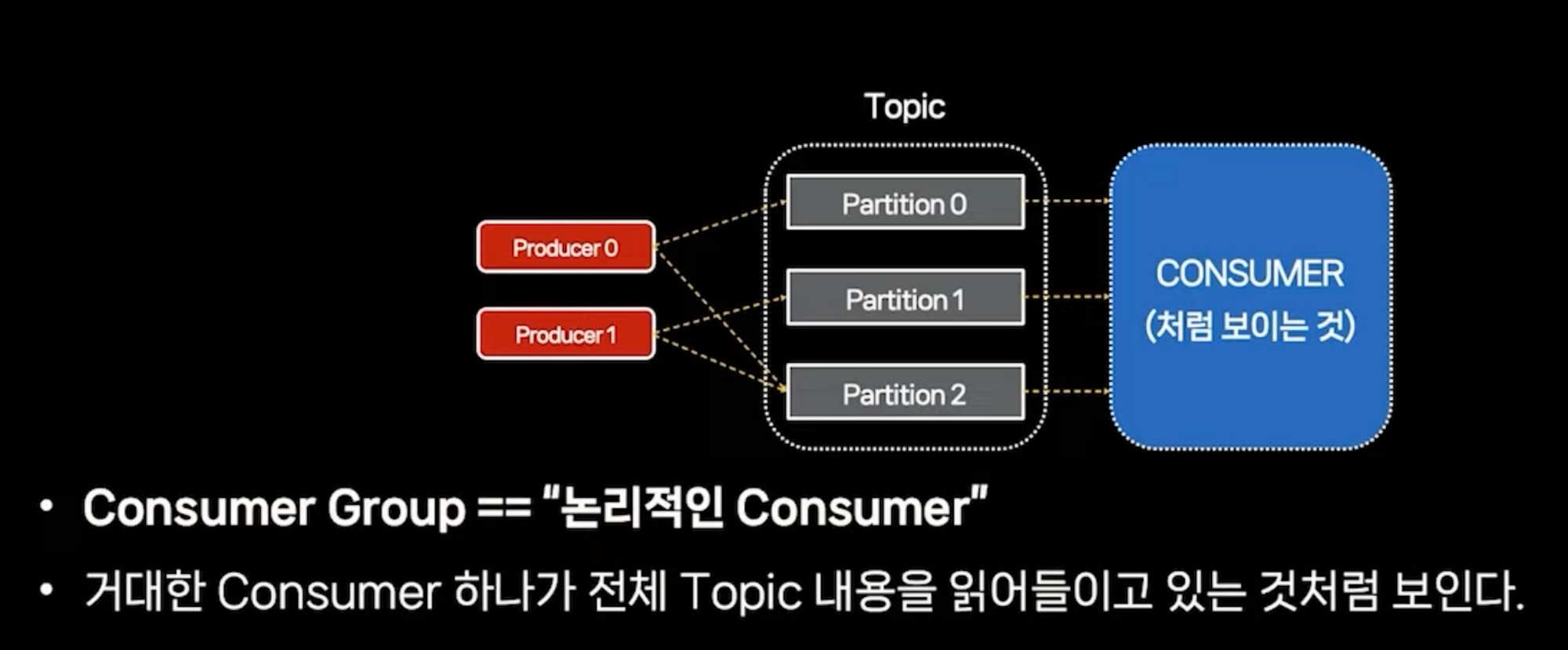
- 소비자 추상화 객체 → 논리적 소비자
- 소비자 그룹 기능이 제대로 작동하려면 두 가지가 필요합니다.
- 파티션 할당 기능
- 중복이나 누락 없이 할당하는 할당 메커니즘
- 오프셋 커밋 기능
- 작업을 계속할 수 있는 저장 및 읽기 메커니즘.
- 파티션 할당 기능
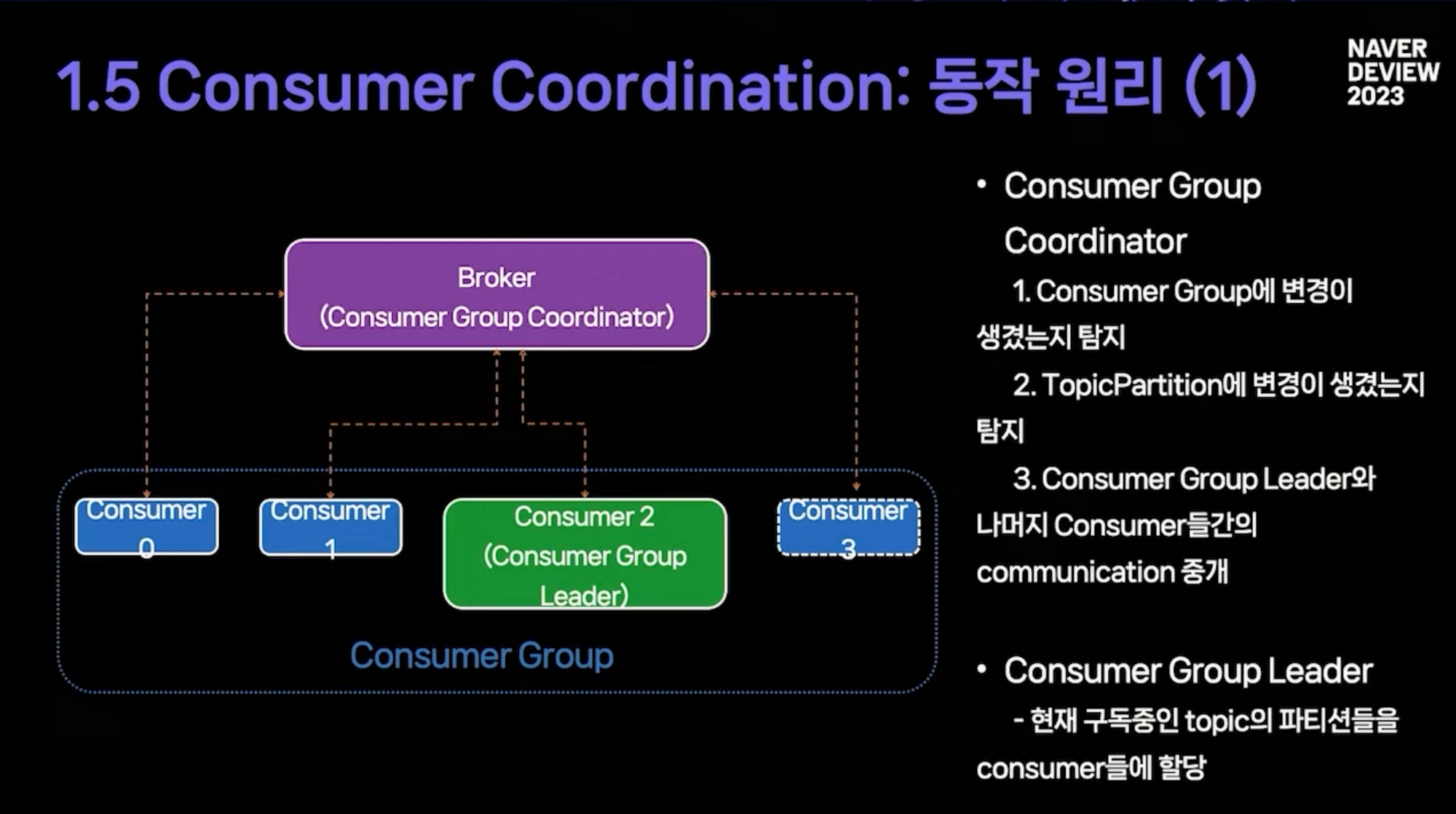
- 서버가 아닌 소비자 그룹 중 하나의 소비자 리더가 되어 토픽의 파티션을 소비자에게 할당합니다.
- 소비자들은 서로 직접적으로 소통하지 않고 소비자 그룹 코디네이터 역할을 하는 브로커를 통해 간접적으로 소통한다.
- 브로커를 다시 시작할 필요 없이 유연하고 확장 가능한 파티션 할당을 지원하도록 이러한 방식으로 구성됩니다.
- max.poll.interval.ms: 소비자가 주제를 폴링하는 최대 시간
- session.timeout.ms: 소비자가 백그라운드 스레드에 의해 소비자 조정자에게 하트비트를 전송하지 않고 실행할 수 있는 최대 시간입니다.
- 하트비트.간격.ms
- partition.assignment.strategy: consumerPartitionAssignor 클래스 목록
- 파티션 할당 전략으로 선택
- 그룹.인스턴스.id
- 정상적인 재부팅 전에 할당된 파티션이 재할당되기 때문에 재조정이 없습니다.
- 간단한 포드 재시작으로 파티션 재조정이 발생하지 않도록 방지
- Kafka Streams는 이 설정을 내부적으로 사용합니다.
요약
- 카프카 컨슈머는 컨슈머 그룹의 개념을 가지고 있으며, 같은 컨슈머 그룹에 속한 컨슈머는 토픽을 읽을 때 자동으로 파티션으로 나뉜다.
- 클라우드 환경에서 컨슈머 그룹 기능을 사용하기가 쉽지 않으며, 2.x 이후에 업데이트된 기능과 설정을 적절히 사용하면 문제를 예방할 수 있습니다.
- 랙 인식 최적화가 있는 파티션 할당자가 가능하며 그리 멀지 않은 미래에 일반적인 기능이 될 것입니다.